Why is multi-threaded Python so slow?
What’s up with multi-threaded Python being so slow? The truth and possible workarounds.

TL;DR
Contrary to what one might expect, and due to the Python Global Interpreter Lock (GIL), one will not see a reduction in overall processing time when using multi-threading to compute pure CPU-bound Python code. The official documentation explains that the GIL is the bottleneck preventing threads from executing completely concurrently resulting in the CPU being underutilised [1, 2].
To effectively use the CPU one needs to side-step the GIL and make use of the ProcessPoolExecutor or Process modules [3, 4]. Presented below are code examples showing how the ProcessPoolExecutor and Process modules can be used instead of Thread and ThreadPoolExecutor to reduce overall processing time. Alternatively one can also call packages not written in Python like NumPy or SciPy more able to efficiently utilise the CPU [5].
Introduction
When I started using Python I was often warned about its multi-threading being slow. I was told Python is essentially single-threaded. Thoroughly warned I decided to play it safe and basically never use the Threading package opting instead for the functionality from the asyncio package, where I occasionally combined it with the ProcessPoolExecutor module as required. The supposed problem, therefore, of Python’s multi-threading being slow did not inconvenience me that much due to my required processing being more I/O bound, meaning most of the time I only had to deal with waiting for external I/O for which asyncio sleep was perfect.
However recently curiosity got the better of me and I decided to verify for myself if multi-threaded Python really is as slow as I was led to believe. In the sections below I present my findings on reviewing the official documentation and also doing some tests of my own.
Is Python really single-threaded?
First and foremost I wanted to ascertain if Python is able to spawn threads at all. I, therefore, prepared a very simple Python multi-threaded test case for execution on a multi-core CPU. The code was executed and the task manager monitored to see if the parent process spawned any threads identifiable by the operating system. The test showed the threads spawned by the process were definitely present. Below is a screen capture of the task manager output. It is therefore clear Python does have multi-threading capability.
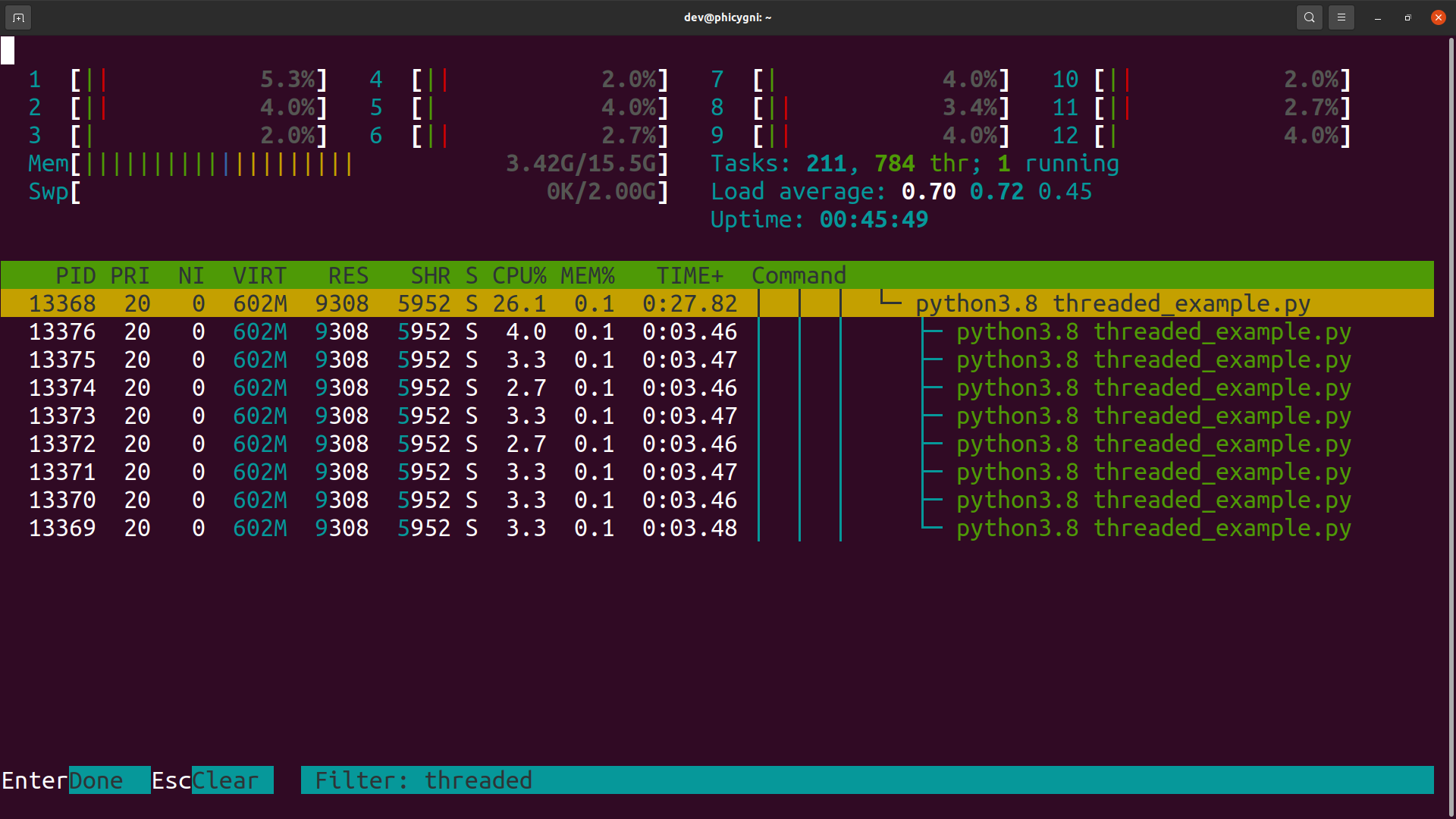
What does the official documentation say with regards to multi-threading?
The documentation page for the multiprocessing package states that: “The multiprocessing package offers both local and remote concurrency, effectively side-stepping the Global Interpreter Lock by using subprocesses instead of threads. Due to this, the multiprocessing module allows the programmer to fully leverage multiple processors on a given machine.” [4]
Furthermore, the following is said with regards to the GIL on the FAQ page: “This doesn’t mean that you can’t make good use of Python on multi-CPU machines! You just have to be creative with dividing the work up between multiple processes rather than multiple threads. The ProcessPoolExecutor class in the new concurrent.futures module provides an easy way of doing so…” [2]
Members of the Python community have also been known to sometimes, for the record, point out their frustration with the apparent underperformance with regards to multi-threaded Python code. Case in point by Juergen Brendel in an open letter to Guido van Rossum (the creator of Python) where he states: “For those who are not familiar with the issue: The GIL is a single lock inside of the Python interpreter, which effectively prevents multiple threads from being executed in parallel, even on multi-core or multi-CPU systems!” [6]
It is therefore clear, without any ambiguity, multi-threaded Python is unable to optimally utilise multi-core CPUs due to the GIL. The documentation recommends processes be used instead.
A series of tests
To independently verify the recommendations of the documentation, with regards to optimal concurrency, a series of tests were prepared for evaluation. All tests are written in pure Python and execute the same identical CPU-bound code but use different concurrency strategies. The tests are:
| Test # | Description |
|---|---|
| 1 | Execute a function eight times serially without any threads or any means of concurrency. This is the baseline test. |
| 2 | Execute a function eight times concurrently using module Thread. |
| 3 | Execute a function eight times using module ThreadPoolExecutor. |
| 4 | Execute a function eight times using module ThreadPoolExecutor inside an asyncio loop. |
| 5 | Execute a function eight times using module Process. |
| 6 | Execute a function eight times using module ProcessPoolExecutor inside an asyncio loop. |
Each test was repeated ten times and the average overall processing time recorded for comparison. The test source code is available via this Github repo.
Test 1: Completely serialised execution
#!/usr/bin/env python3.8
"""
Test 1: The baseline test without threads or using
any packages.
"""
import time
def vThreadFunction():
"""Function to do CPU-bound work.
Args:
Returns:
"""
iResult = 0
for iCnt in range(50000000):
iResult += iCnt
def vMain():
fTimePrefCountStart = time.perf_counter()
# Call the function eight times
for _ in range(8):
vThreadFunction()
fTimePrefCountEnd = time.perf_counter()
print(f"Delta time {fTimePrefCountEnd - fTimePrefCountStart} [s]")
if __name__ == "__main__":
vMain()
Test 2: Using the Thread module
#!/usr/bin/env python3.8
"""
Test 2: Making use of the threading module to spawn
eight threads.
"""
import threading
import time
def vThreadFunction():
"""Function to do CPU-bound work.
Args:
Returns:
"""
iResult = 0
for iCnt in range(50000000):
iResult += iCnt
def vMain():
lstThreads = []
fTimePrefCountStart = time.perf_counter()
# Create eight threads
for _ in range(8):
objThread = threading.Thread(target=vThreadFunction)
objThread.daemon = False
lstThreads.append(objThread)
for objThread in lstThreads:
objThread.start()
for objThread in lstThreads:
objThread.join()
fTimePrefCountEnd = time.perf_counter()
print(f"Delta time {fTimePrefCountEnd - fTimePrefCountStart} [s]")
return
if __name__ == "__main__":
vMain()
Test 3: Using the ThreadPoolExecutor module
#!/usr/bin/env python3.8
"""
Test 3: Making use of the ThreadPoolExecutor
from the concurrent package.
"""
import time
from concurrent.futures import ThreadPoolExecutor, wait
def iThreadFunction():
"""Function to do CPU-bound work.
Args:
Returns:
"""
iResult = 0
for i in range(50000000):
iResult += i
def vMain():
# Create an executor with a maximum of eight workers
objExecutor = ThreadPoolExecutor(max_workers=8)
lstFutures = []
fTimePrefCountStart = time.perf_counter()
# Submit eight tasks to the executor
for _ in range(8):
lstFutures.append(objExecutor.submit(iThreadFunction))
# Wait for all threads to complete
wait(lstFutures)
fTimePrefCountEnd = time.perf_counter()
print(f"Delta time {fTimePrefCountEnd - fTimePrefCountStart} [s]")
objExecutor.shutdown(wait=False)
if __name__ == "__main__":
vMain()
Test 4: Using the ThreadPoolExecutor inside asyncio loop
#!/usr/bin/env python3.8
"""
Test 4: Combining the ThreadPoolExecutor
with the asyncio package.
"""
import time
from concurrent.futures import ThreadPoolExecutor
import asyncio
def vThreadFunction():
"""Function to do CPU-bound work.
Args:
Returns:
"""
iResult = 0
for iCnt in range(50000000):
iResult += iCnt
async def vMain():
loop = asyncio.get_running_loop()
lstFutures = []
# Create an executor with a maximum of eight workers
objExecutor = ThreadPoolExecutor(max_workers=8)
fTimePrefCountStart = time.perf_counter()
# Create eight threads using the executor
for _ in range(8):
lstFutures.append(loop.run_in_executor(objExecutor, vThreadFunction))
# Wait for all threads to complete
await asyncio.wait(lstFutures)
fTimePrefCountEnd = time.perf_counter()
print(f"Delta time {fTimePrefCountEnd - fTimePrefCountStart} [s]")
objExecutor.shutdown(wait=False)
if __name__ == "__main__":
# Python 3.7+
asyncio.run(vMain())
Test 5: Using the Process module
#!/usr/bin/env python3.8
"""
Test 5: Making use of the multiprocessing package.
"""
import time
from multiprocessing import Process
def vProcessFunction():
"""Function to do CPU-bound work.
Args:
Returns:
"""
iResult = 0
for iCnt in range(50000000):
iResult += iCnt
def vMain():
lstProcesses = []
# Create eight processes
for _ in range(8):
lstProcesses.append(Process(target=vProcessFunction))
fTimePrefCountStart = time.perf_counter()
# Start all the processes
for objProcess in lstProcesses:
objProcess.start()
# Wait for all processes to complete
for objProcess in lstProcesses:
objProcess.join()
fTimePrefCountEnd = time.perf_counter()
print(f"Delta time {fTimePrefCountEnd - fTimePrefCountStart} [s]")
if __name__ == "__main__":
vMain()
Test 6: Using the ProcessPoolExecutor inside asyncio loop
#!/usr/bin/env python3.8
"""
Test 6: Combining ProcessPoolExecutor with
the asyncio package.
"""
import time
from concurrent.futures import ProcessPoolExecutor
import asyncio
def vProcessFunction():
"""Function to do CPU-bound work.
Args:
Returns:
"""
iResult = 0
for iCnt in range(50000000):
iResult += iCnt
async def vMain():
loop = asyncio.get_running_loop()
lstFutures = []
# Create an executor with a maximum of eight workers
objExecutor = ProcessPoolExecutor(max_workers=8)
fTimePrefCountStart = time.perf_counter()
# Create eight processes using the executor
for _ in range(8):
lstFutures.append(loop.run_in_executor(objExecutor, vProcessFunction))
# Wait for all processes to complete
await asyncio.wait(lstFutures)
fTimePrefCountEnd = time.perf_counter()
print(f"Delta time {fTimePrefCountEnd - fTimePrefCountStart} [s]")
if __name__ == "__main__":
# Python 3.7+
asyncio.run(vMain())
Test results
The test results show multi-threaded code is indeed significantly slower compared to multi-process code or even serialised execution. Surprisingly the baseline test with no concurrency at all outperformed all of the threaded tests.
The test result also show, as stated in the documentation, using processes will provide far better CPU utilisation compared to threaded solutions. This is evident by the overall processing time being greatly reduced when processes are used.
| Test # | Test description | Avg. processing time [s] | Perc. time of baseline [%] |
|---|---|---|---|
| 1 | Execute a function eight times serially without any threads or any means of concurrency. This is the baseline test. | 10.4 | N/A |
| 2 | Execute a function eight times concurrently using module Thread. | 13.3 | 128% |
| 3 | Execute a function eight times using module ThreadPoolExecutor. | 13.6 | 131% |
| 4 | Execute a function eight times using module ThreadPoolExecutor inside an asyncio loop. | 13.8 | 133% |
| 5 | Execute a function eight times using module Process. | 2.2 | 21% |
| 6 | Execute a function eight times using module ProcessPoolExecutor inside an asyncio loop. | 2.1 | 20% |
Conclusion
Making use of the Python Thread or ThreadPoolExecutor modules to run pure CPU-bound code will not result in true concurrent execution. In fact a non-threaded completely serialised design will outperform a threaded one. This is due to the Python GIL being the bottleneck preventing threads from running completely concurrently. The best possible CPU utilisation can be achieved by making use of the ProcessPoolExecutor or Process modules which circumvents the GIL and make code run more concurrently.
References
[1] https://wiki.python.org/moin/GlobalInterpreterLock
[2] https://docs.python.org/3/faq/library.html#can-t-we-get-rid-of-the-global-interpreter-lock
[3] https://docs.python.org/3.8/library/concurrent.futures.html#processpoolexecutor
[4] https://docs.python.org/3.8/library/multiprocessing.html#introduction
[5] https://scipy-cookbook.readthedocs.io/items/ParallelProgramming.html
[6] https://www.snaplogic.com/blog/an-open-letter-to-guido-van-rossum-mr-rossum-tear-down-that-gil